4 Data Frame 處理:dplyr
(投影片 /
程式碼 /
影片)
This material is largely based on Garrett Grolemund’s introduction to dplyr
4.1 Why dplyr?
-
上週介紹過篩選 data frame 的方法:
df[<vector 1>, <vector 2>]。但這種方法有一個缺點:隨著篩選條件越來越多,篩選 data frame 的指令會越來越複雜,變得難以閱讀,例如:library(tibble) df <- as_tibble(iris) # How long does it take to understand the command below? df[(df$Species == "setosa") & (df$Sepal.Length < 5.8), c("Species", "Sepal.Width")]#> # A tibble: 49 x 2 #> Species Sepal.Width #> <fct> <dbl> #> 1 setosa 3.5 #> 2 setosa 3 #> 3 setosa 3.2 #> 4 setosa 3.1 #> 5 setosa 3.6 #> 6 setosa 3.9 #> 7 setosa 3.4 #> 8 setosa 3.4 #> 9 setosa 2.9 #> 10 setosa 3.1 #> # … with 39 more rows 套件
dplyr目的就是為了使這個過程變得更加容易:讓處理 data frame 的指令變得直覺易懂。
4.2 讀取表格式資料 (.csv)
-
可使用 RStudio
Environment Pane > Import Dataset > From Text (readr)...,或直接使用指令:babynames <- readr::read_csv('babynames.csv') babynames#> # A tibble: 177,780 x 5 #> year sex name n prop #> <dbl> <chr> <chr> <dbl> <dbl> #> 1 1880 M John 9655 0.0815 #> 2 1880 M William 9532 0.0805 #> 3 1880 M James 5927 0.0501 #> 4 1880 M Charles 5348 0.0452 #> 5 1880 M George 5126 0.0433 #> 6 1880 M Frank 3242 0.0274 #> 7 1880 M Joseph 2632 0.0222 #> 8 1880 M Thomas 2534 0.0214 #> 9 1880 M Henry 2444 0.0206 #> 10 1880 M Robert 2415 0.0204 #> # … with 177,770 more rows如此便會將外部檔案讀入成
tibble(data frame)
4.4 select(): 篩選出特定變項
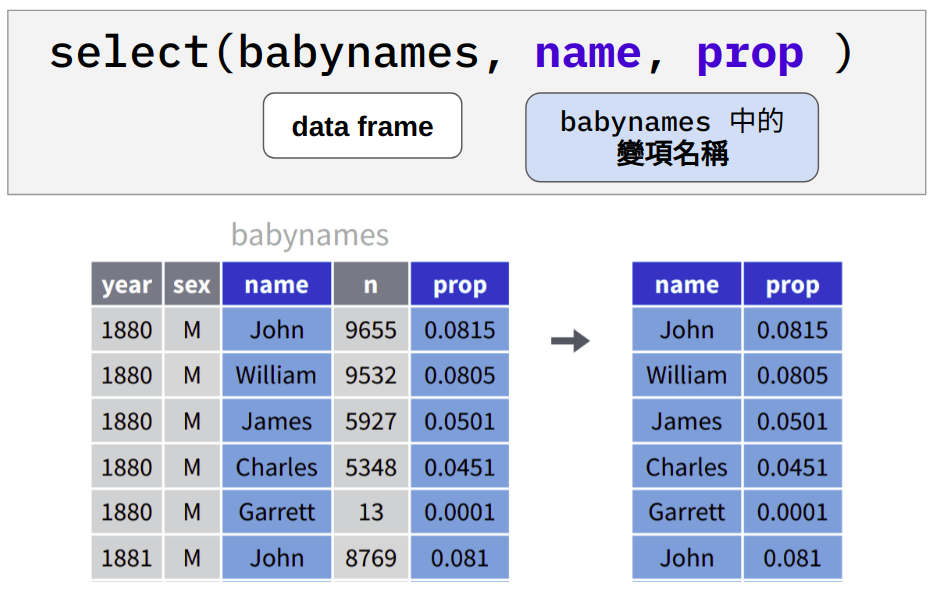
Figure 4.1: 篩選出 babynames 中的 name 與 prop 變項。
library(dplyr)
# select(<data frame>, <variable name in df>, <variable name in df>, ...)
select(babynames, name, prop) # eqivalent to babynames[, c("name", "prop")]#> # A tibble: 177,780 x 2
#> name prop
#> <chr> <dbl>
#> 1 John 0.0815
#> 2 William 0.0805
#> 3 James 0.0501
#> 4 Charles 0.0452
#> 5 George 0.0433
#> 6 Frank 0.0274
#> 7 Joseph 0.0222
#> 8 Thomas 0.0214
#> 9 Henry 0.0206
#> 10 Robert 0.0204
#> # … with 177,770 more rows4.4.1 helpers
-
dplyr額外提供了一些函數,方便使用者依據變項名稱的特性去篩選變項:iris_ <- as_tibble(iris) select(iris_, starts_with('Sepal'))#> # A tibble: 150 x 2 #> Sepal.Length Sepal.Width #> <dbl> <dbl> #> 1 5.1 3.5 #> 2 4.9 3 #> 3 4.7 3.2 #> 4 4.6 3.1 #> 5 5 3.6 #> 6 5.4 3.9 #> 7 4.6 3.4 #> 8 5 3.4 #> 9 4.4 2.9 #> 10 4.9 3.1 #> # … with 140 more rows#> # A tibble: 150 x 2 #> Sepal.Width Petal.Width #> <dbl> <dbl> #> 1 3.5 0.2 #> 2 3 0.2 #> 3 3.2 0.2 #> 4 3.1 0.2 #> 5 3.6 0.2 #> 6 3.9 0.4 #> 7 3.4 0.3 #> 8 3.4 0.2 #> 9 2.9 0.2 #> 10 3.1 0.1 #> # … with 140 more rows#> # A tibble: 150 x 4 #> Sepal.Length Sepal.Width Petal.Length Petal.Width #> <dbl> <dbl> <dbl> <dbl> #> 1 5.1 3.5 1.4 0.2 #> 2 4.9 3 1.4 0.2 #> 3 4.7 3.2 1.3 0.2 #> 4 4.6 3.1 1.5 0.2 #> 5 5 3.6 1.4 0.2 #> 6 5.4 3.9 1.7 0.4 #> 7 4.6 3.4 1.4 0.3 #> 8 5 3.4 1.5 0.2 #> 9 4.4 2.9 1.4 0.2 #> 10 4.9 3.1 1.5 0.1 #> # … with 140 more rowsdf <- tibble(x_1 = 1:10, x_2 = 11:20, x_3 = 21:30, x_4 = 31:40, x_5 = 41:50) select(df, num_range("x_", 2:4))#> # A tibble: 10 x 3 #> x_2 x_3 x_4 #> <int> <int> <int> #> 1 11 21 31 #> 2 12 22 32 #> 3 13 23 33 #> 4 14 24 34 #> 5 15 25 35 #> 6 16 26 36 #> 7 17 27 37 #> 8 18 28 38 #> 9 19 29 39 #> 10 20 30 40# You can still quote the variable names select(df, "x_1", "x_2", "x_3")#> # A tibble: 10 x 3 #> x_1 x_2 x_3 #> <int> <int> <int> #> 1 1 11 21 #> 2 2 12 22 #> 3 3 13 23 #> 4 4 14 24 #> 5 5 15 25 #> 6 6 16 26 #> 7 7 17 27 #> 8 8 18 28 #> 9 9 19 29 #> 10 10 20 30#> # A tibble: 10 x 3 #> x_1 x_2 x_3 #> <int> <int> <int> #> 1 1 11 21 #> 2 2 12 22 #> 3 3 13 23 #> 4 4 14 24 #> 5 5 15 25 #> 6 6 16 26 #> 7 7 17 27 #> 8 8 18 28 #> 9 9 19 29 #> 10 10 20 30
4.5 filter(): 篩選出特定觀察值
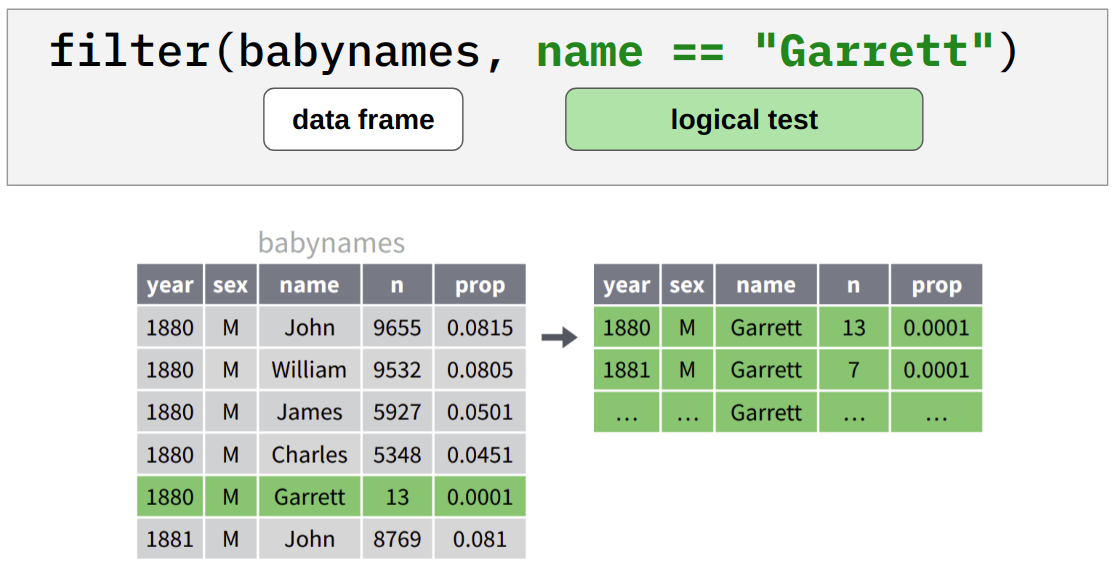
Figure 4.2: 篩選出 babynames 中的 name 為 “Garrett” 的觀察值。
# filter(<data frame>, <logical test on variable>, <logical test on variable>, ...)
filter(babynames, name == "Garrett")#> # A tibble: 13 x 5
#> year sex name n prop
#> <dbl> <chr> <chr> <dbl> <dbl>
#> 1 1880 M Garrett 13 0.000110
#> 2 1881 M Garrett 7 0.0000646
#> 3 1882 M Garrett 15 0.000123
#> 4 1883 M Garrett 13 0.000116
#> 5 1884 M Garrett 15 0.000122
#> 6 1885 M Garrett 9 0.0000776
#> 7 2013 M Garrett 1613 0.000800
#> 8 2013 F Garrett 5 0.0000026
#> 9 2014 M Garrett 1562 0.000764
#> 10 2014 F Garrett 6 0.00000307
#> 11 2015 M Garrett 1349 0.000662
#> 12 2016 M Garrett 1146 0.000568
#> 13 2017 M Garrett 1056 0.000538
filter(babynames, (name == "Garrett") & (year < 1885))#> # A tibble: 5 x 5
#> year sex name n prop
#> <dbl> <chr> <chr> <dbl> <dbl>
#> 1 1880 M Garrett 13 0.000110
#> 2 1881 M Garrett 7 0.0000646
#> 3 1882 M Garrett 15 0.000123
#> 4 1883 M Garrett 13 0.000116
#> 5 1884 M Garrett 15 0.000122
filter(babynames, name == "Garrett", year < 1885) # equivalent to the previous command#> # A tibble: 5 x 5
#> year sex name n prop
#> <dbl> <chr> <chr> <dbl> <dbl>
#> 1 1880 M Garrett 13 0.000110
#> 2 1881 M Garrett 7 0.0000646
#> 3 1882 M Garrett 15 0.000123
#> 4 1883 M Garrett 13 0.000116
#> 5 1884 M Garrett 15 0.000122
4.6 arrange(): 重新排序觀察值
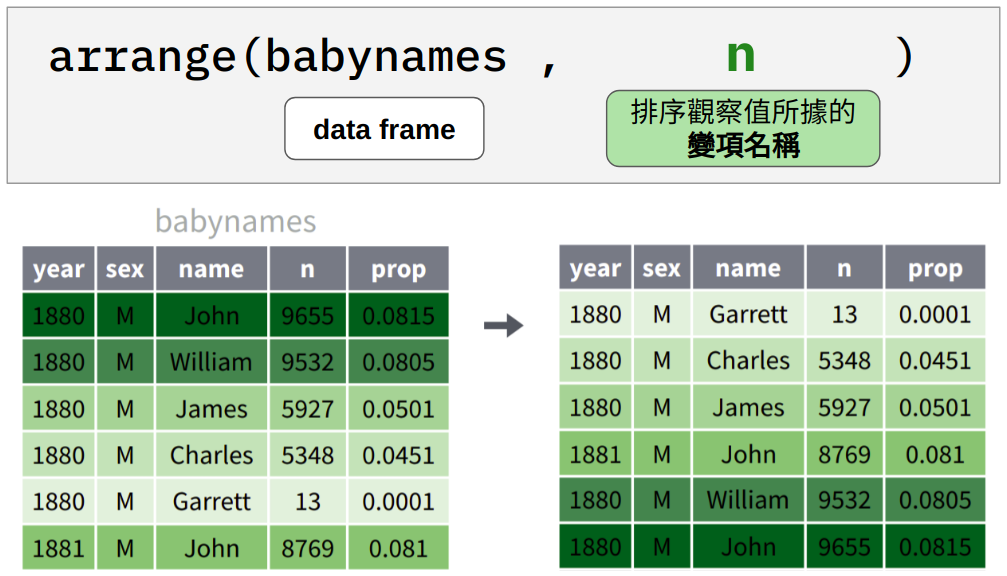
Figure 4.3: 依據變項 n 的大小由小至大排序 babynames 中的觀察值。
#arrange(<data frame>, <variable name in df>, <variable name in df>, ...)
arrange(babynames, n)#> # A tibble: 177,780 x 5
#> year sex name n prop
#> <dbl> <chr> <chr> <dbl> <dbl>
#> 1 1880 M Ab 5 0.0000422
#> 2 1880 M Abbott 5 0.0000422
#> 3 1880 M Agustus 5 0.0000422
#> 4 1880 M Albertus 5 0.0000422
#> 5 1880 M Almer 5 0.0000422
#> 6 1880 M Alphonso 5 0.0000422
#> 7 1880 M Alvia 5 0.0000422
#> 8 1880 M Artie 5 0.0000422
#> 9 1880 M Arvid 5 0.0000422
#> 10 1880 M Ashby 5 0.0000422
#> # … with 177,770 more rows#> # A tibble: 177,780 x 5
#> year sex name n prop
#> <dbl> <chr> <chr> <dbl> <dbl>
#> 1 2013 F Sophia 21213 0.0110
#> 2 2013 F Emma 20936 0.0109
#> 3 2014 F Emma 20924 0.0107
#> 4 2015 F Emma 20435 0.0105
#> 5 2014 F Olivia 19791 0.0101
#> 6 2017 F Emma 19738 0.0105
#> 7 2015 F Olivia 19669 0.0101
#> 8 2015 M Noah 19613 0.00962
#> 9 2016 F Emma 19471 0.0101
#> 10 2016 F Olivia 19327 0.0100
#> # … with 177,770 more rows
# Order first by `year` then by `name`
arrange(babynames, year, name)#> # A tibble: 177,780 x 5
#> year sex name n prop
#> <dbl> <chr> <chr> <dbl> <dbl>
#> 1 1880 M Aaron 102 0.000861
#> 2 1880 M Ab 5 0.0000422
#> 3 1880 F Abbie 71 0.000727
#> 4 1880 M Abbott 5 0.0000422
#> 5 1880 F Abby 6 0.0000615
#> 6 1880 M Abe 50 0.000422
#> 7 1880 M Abel 9 0.0000760
#> 8 1880 F Abigail 12 0.000123
#> 9 1880 M Abner 27 0.000228
#> 10 1880 M Abraham 81 0.000684
#> # … with 177,770 more rows
# Order first by `name` then by `year`
arrange(babynames, name, year)#> # A tibble: 177,780 x 5
#> year sex name n prop
#> <dbl> <chr> <chr> <dbl> <dbl>
#> 1 2013 M Aaban 14 0.00000694
#> 2 2014 M Aaban 16 0.00000783
#> 3 2015 M Aaban 15 0.00000736
#> 4 2016 M Aaban 9 0.00000446
#> 5 2017 M Aaban 11 0.0000056
#> 6 2014 F Aabha 9 0.00000461
#> 7 2015 F Aabha 7 0.0000036
#> 8 2016 F Aabha 7 0.00000363
#> 9 2016 M Aabid 5 0.00000248
#> 10 2016 M Aabir 5 0.00000248
#> # … with 177,770 more rows
4.7 %>%: Connecting multiple dplyr functions together
-
dplyr的函數一次只能做一件事情:select()只能用來篩選變項、filter()只能用來篩選觀察值、arrange()只能用來排序資料。但資料整理的過程中往往需要一次做很多事情,例如,可能需要在篩選完觀察值之後再進行排序。如果每次呼叫完一個函數就必須將結果儲存在一個變項,會讓整理資料的過程變得很麻煩,例如:girls2017 <- filter(babynames, year == 2017, sex == "F") girls2017 <- select(girls2017, name, n) girls2017 <- arrange(girls2017, desc(n)) girls2017#> # A tibble: 18,309 x 2 #> name n #> <chr> <dbl> #> 1 Emma 19738 #> 2 Olivia 18632 #> 3 Ava 15902 #> 4 Isabella 15100 #> 5 Sophia 14831 #> 6 Mia 13437 #> 7 Charlotte 12893 #> 8 Amelia 11800 #> 9 Evelyn 10675 #> 10 Abigail 10551 #> # … with 18,299 more rows -
dplyr(精確地說是magrittr) 因此提供了一種特殊的 binary operator%>%,讓使用者可以將位在%>%左側之表達式的執行結果 (回傳值) 做為位在%>%右側之函數的第一個輸入值 (引數, argument):# Two equivalent expressions filter(babynames, year == 2017, sex == "F") cat('\n\n') # 讓印出結果比較好看 babynames %>% filter(year == 2017, sex == "F")#> # A tibble: 18,309 x 5 #> year sex name n prop #> <dbl> <chr> <chr> <dbl> <dbl> #> 1 2017 F Emma 19738 0.0105 #> 2 2017 F Olivia 18632 0.00994 #> 3 2017 F Ava 15902 0.00848 #> 4 2017 F Isabella 15100 0.00805 #> 5 2017 F Sophia 14831 0.00791 #> 6 2017 F Mia 13437 0.00717 #> 7 2017 F Charlotte 12893 0.00688 #> 8 2017 F Amelia 11800 0.00629 #> 9 2017 F Evelyn 10675 0.00569 #> 10 2017 F Abigail 10551 0.00563 #> # … with 18,299 more rows #> #> #> # A tibble: 18,309 x 5 #> year sex name n prop #> <dbl> <chr> <chr> <dbl> <dbl> #> 1 2017 F Emma 19738 0.0105 #> 2 2017 F Olivia 18632 0.00994 #> 3 2017 F Ava 15902 0.00848 #> 4 2017 F Isabella 15100 0.00805 #> 5 2017 F Sophia 14831 0.00791 #> 6 2017 F Mia 13437 0.00717 #> 7 2017 F Charlotte 12893 0.00688 #> 8 2017 F Amelia 11800 0.00629 #> 9 2017 F Evelyn 10675 0.00569 #> 10 2017 F Abigail 10551 0.00563 #> # … with 18,299 more rows如此便可將整理資料的過程改寫成一條「由一個個函數串成的」指令,如下
#> # A tibble: 18,309 x 2 #> name n #> <chr> <dbl> #> 1 Emma 19738 #> 2 Olivia 18632 #> 3 Ava 15902 #> 4 Isabella 15100 #> 5 Sophia 14831 #> 6 Mia 13437 #> 7 Charlotte 12893 #> 8 Amelia 11800 #> 9 Evelyn 10675 #> 10 Abigail 10551 #> # … with 18,299 more rows
4.8 Functions for “deriving information” in dplyr
- 上文介紹的內容是關於「如何篩選或排序既有的資料」。但有時候,我們需要從既有的資料去產出新的資料,例如根據既有資料的某些變項計算出新的變項,或是對既有資料做出一些摘要統計。面對這些需求,
dplyr提供了 2 個重要的函數:-
mutate(): 在 data frame 裡建立一個新的變項 -
summarise(): 對 data frame 裡的變項進行摘要,例如,計算某個變項的算術平均數、最大(小)值、變異數等-
group_by()是dplyr中常與summarise()搭配使用的函數,其功能是將觀察值依據某些「類別變項」進行分類,如此summarise()就可依據分組後的結果去計算出各個組別內變項的摘要。例如,我們可以先使用group_by()將babynames的觀察值依據性別 (sex) 進行分類,再使用summarise()計算出這兩個性別的姓名 (name) 的數量。
-
-
4.9 mutate(): 建立新變項
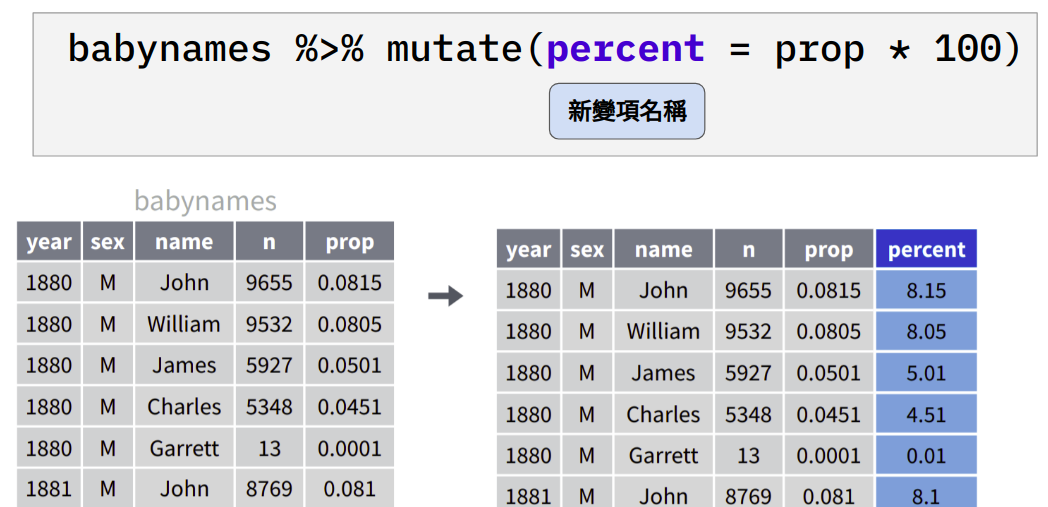
Figure 4.4: 依據變項 prop 製造新變項 percent。
-
mutate()背後運作的原理是 R 的向量式運算,亦即,它是以一個變項 (i.e. 向量) 當作操作的單元。因此,用於mutate()內的函數必須是所謂的 “vectorized function”:vectorized function 是指可接受一個或多個 vector 當作輸入值,並且會回傳長度相等的 vector的函數。
babynames %>% mutate(percent = prop*100)#> # A tibble: 177,780 x 6
#> year sex name n prop percent
#> <dbl> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 1880 M John 9655 0.0815 8.15
#> 2 1880 M William 9532 0.0805 8.05
#> 3 1880 M James 5927 0.0501 5.01
#> 4 1880 M Charles 5348 0.0452 4.52
#> 5 1880 M George 5126 0.0433 4.33
#> 6 1880 M Frank 3242 0.0274 2.74
#> 7 1880 M Joseph 2632 0.0222 2.22
#> 8 1880 M Thomas 2534 0.0214 2.14
#> 9 1880 M Henry 2444 0.0206 2.06
#> 10 1880 M Robert 2415 0.0204 2.04
#> # … with 177,770 more rows#> # A tibble: 177,780 x 6
#> year sex name n prop sex2
#> <dbl> <chr> <chr> <dbl> <dbl> <chr>
#> 1 1880 M John 9655 0.0815 male
#> 2 1880 M William 9532 0.0805 male
#> 3 1880 M James 5927 0.0501 male
#> 4 1880 M Charles 5348 0.0452 male
#> 5 1880 M George 5126 0.0433 male
#> 6 1880 M Frank 3242 0.0274 male
#> 7 1880 M Joseph 2632 0.0222 male
#> 8 1880 M Thomas 2534 0.0214 male
#> 9 1880 M Henry 2444 0.0206 male
#> 10 1880 M Robert 2415 0.0204 male
#> # … with 177,770 more rows
4.10 summarise(): 對變項進行摘要
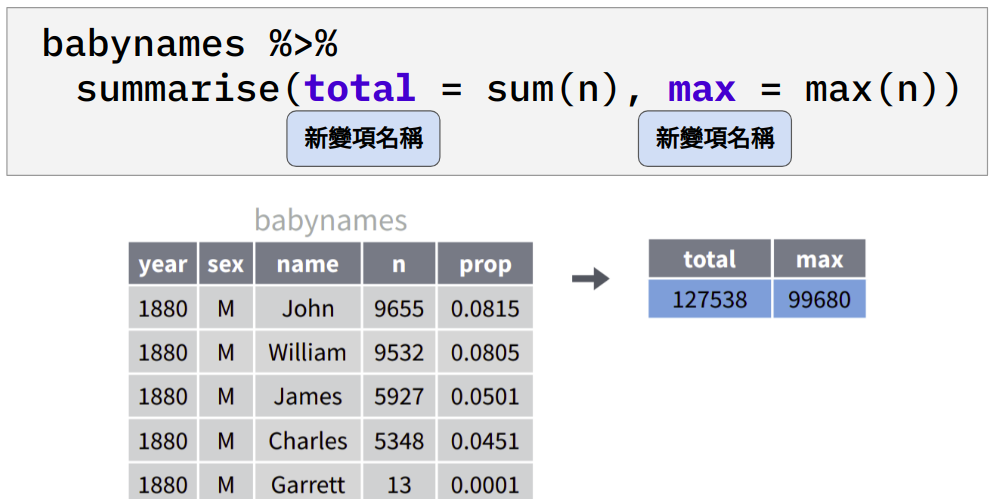
Figure 4.5: 對變項 n 進行摘要 (計算總和與最大值),並將摘要的結果儲存於兩個新變項 total 與 max。
#> # A tibble: 1 x 2
#> total max
#> <dbl> <dbl>
#> 1 19538552 21213
babynames %>% summarise(num_of_rows = n(), num_of_names = n_distinct(name))#> # A tibble: 1 x 2
#> num_of_rows num_of_names
#> <int> <int>
#> 1 177780 45953
4.10.1 group_by(): 先分類再摘要
pollution <- tibble::tribble(
~city, ~size, ~amount,
"New York", "large", 23,
"New York", "small", 14,
"London", "large", 22,
"London", "small", 16,
"Beijing", "large", 121,
"Beijing", "small", 56
)
pollution#> # A tibble: 6 x 3
#> city size amount
#> <chr> <chr> <dbl>
#> 1 New York large 23
#> 2 New York small 14
#> 3 London large 22
#> 4 London small 16
#> 5 Beijing large 121
#> 6 Beijing small 56#> # A tibble: 3 x 4
#> city mean sum count
#> <chr> <dbl> <dbl> <int>
#> 1 Beijing 88.5 177 2
#> 2 London 19 38 2
#> 3 New York 18.5 37 2
Figure 4.6: 先將 pollution 的觀察值依據變項 city 分成 3 組,再各自對 3 組進行摘要 (計算污染量平均與總和) 求得之摘要表。
pollution %>%
group_by(city, size) %>%
summarise(mean = mean(amount),
sum = sum(amount),
count = n())#> # A tibble: 6 x 5
#> # Groups: city [3]
#> city size mean sum count
#> <chr> <chr> <dbl> <dbl> <int>
#> 1 Beijing large 121 121 1
#> 2 Beijing small 56 56 1
#> 3 London large 22 22 1
#> 4 London small 16 16 1
#> 5 New York large 23 23 1
#> 6 New York small 14 14 1參考資源
- Wickham, H., & Grolemund, G. (2017). R for Data Science: Data transformation
- Grolemund, G. (2019). Transform Data with dplyr