3 Base R (II)
3.1 list
vector 是 R 裡面最「簡單」的資料結構。有時候我們需要比較更複雜的資料結構處理我們遇到的資料,例如,我們或許需要儲存不同資料類型或是具有階層結構的資料。面對這兩種需求,vector 無能為力,因此需要用到 R 的 list。
-
R 可以透過
list()去製造出 list。list()的使用方式很類似用來製造 vector 的c(),但與c()不同的是,list()-
能使用不同的資料類型
list(TRUE, 1:3, "Hello")#> [[1]] #> [1] TRUE #> #> [[2]] #> [1] 1 2 3 #> #> [[3]] #> [1] "Hello"list('kai' = TRUE, 'pooh' = 1:3, 'tiger' = "Hello")#> $kai #> [1] TRUE #> #> $pooh #> [1] 1 2 3 #> #> $tiger #> [1] "Hello" -
具有階層結構,亦即,
list()裡面可以放入另一個list()#> [[1]] #> [1] 1.1 #> #> [[2]] #> [[2]][[1]] #> [1] 2.1 #> #> [[2]][[2]] #> [1] "Hello"
-
3.1.1 Subsetting
通常我們會習慣為 list 加上名字 (
names),幫助我們更容易處理這種比較複雜的資料結構-
[]: 與 vector 一樣,我們可以透過lst[<char vector of names>]、lst[<integer vector>]或lst[<logical vector>]去 subset list#> $single #> [1] FALSEpooh[2:3]#> $single #> [1] FALSE #> #> $tags #> [1] "ig" "selfie"pooh[c(TRUE, FALSE, TRUE)]#> $age #> [1] 20 #> #> $tags #> [1] "ig" "selfie" 就像
vec[<some vector>]會回傳一部分的 vector (sub-vector);lst[<some vector>]也會回傳一部分的 list (sub-list)。換言之,使用[]時,回傳值的資料結構不會改變。-
我們可以將 list 想像成一列火車,每節車廂是一個長度為 1 的 sub-list,車廂裡面是這個 sub-list 儲存的值。欲取得 sub-list,使用的是
[];欲取得 sub-list 裡面的值 (i.e. 脫去外層的 list),需使用[[]]# 回傳 sub-list typeof(pooh["tags"]) pooh["tags"] # 回傳 list 之內的「值」,在此為一個 char vector typeof(pooh[["tags"]]) pooh[["tags"]]#> [1] "list" #> $tags #> [1] "ig" "selfie" #> #> [1] "character" #> [1] "ig" "selfie"-
lst[["<name>"]]有另一種更簡便的寫法:lst$<name>, e.g.pooh[["tags"]]可改寫成pooh$tags
-
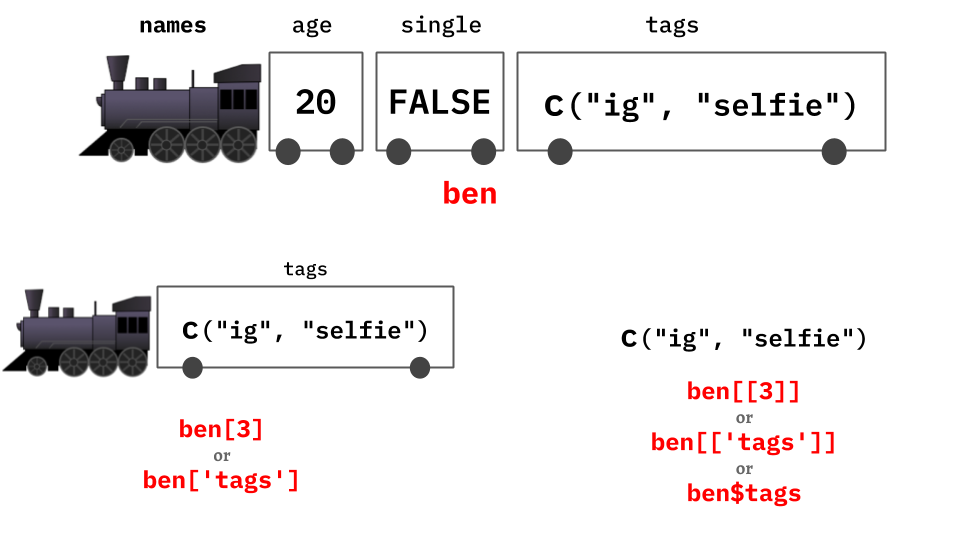
Figure 3.1: List as a train
3.1.2 Nested Structure
a_lst <- list(name = "pooh",
info = list(age = 20,
tags = c("ig", "selfie")))
# Get "selfie"
a_lst[['info']]
a_lst[['info']][['tags']]
a_lst[['info']][['tags']][2]#> $age
#> [1] 20
#>
#> $tags
#> [1] "ig" "selfie"
#>
#> [1] "ig" "selfie"
#> [1] "selfie"
# Another way to get "selfie"
a_lst['info'][[1]]
a_lst['info'][[1]]['tags'][[1]]
a_lst['info'][[1]]['tags'][[1]][2]#> $age
#> [1] 20
#>
#> $tags
#> [1] "ig" "selfie"
#>
#> [1] "ig" "selfie"
#> [1] "selfie"
# Yet another way to get "selfie"
a_lst[[2]]
a_lst[[2]][[2]]
a_lst[[2]][[2]][2]#> $age
#> [1] 20
#>
#> $tags
#> [1] "ig" "selfie"
#>
#> [1] "ig" "selfie"
#> [1] "selfie"
# The most 'readable' way to get "selfie"
a_lst$info
a_lst$info$tags
a_lst$info$tags[2]#> $age
#> [1] 20
#>
#> $tags
#> [1] "ig" "selfie"
#>
#> [1] "ig" "selfie"
#> [1] "selfie"3.2 for loop
上週介紹的條件式 (if-else) 讓我們可以依據不同狀況執行不同的程式碼,藉此能幫助我們寫出更有彈性的程式。迴圈讓我們能重複執行某一區塊的程式碼,如此就不需要重複寫出相同的程式碼。
R 有 for 與 while 迴圈。一般而言,在資料分析時非常少會用到 while 迴圈,因此實習課不作介紹,有興趣的同學可自行參考線上教材或教科書。
-
for loop 的結構如下
for (<變數> in <vector>) { <some code> } for loop 會使
{}內的程式碼重複執行數次,其次數等於<vector>的長度;並且,在第 n 次開始執行{}內的程式碼前,會將<vector>裡的第 n 個元素指派給<變數>。所以在第一次迴圈時,可透過<變數>取得<vector>中的第一個元素;在第二次迴圈時,可取得<vector>中的第二個元素;依此類推,最後一次迴圈則可以透過<變數>取得<vector>中的最後一個元素。
vec <- c("謝", "老師", "好", "帥")
for (word in vec) {
# Will execute 4 times,
# each time a new value from `vec` will be assigned to `word`
print(word)
}#> [1] "謝"
#> [1] "老師"
#> [1] "好"
#> [1] "帥"3.2.1 for loop 的各種型態
- R 的 for 只有一種結構:每次疊代將 vector (或 list) 中的一個元素指派給變數 (
<var> in <vector>)。但因為 R 向量式程式語言的特性,R 的 for 迴圈很容易改寫成其它更方便的型態。
-
有時候我們需要知道迴圈進行到
<vector>的第幾個元素,這時候通常會使用seq_along(<vector>)去製造出與<vector>等長的整數序列 (e.g.seq_along(c('a', 'b', 'c'))會回傳1 2 3),如此我們便可知道進行到第幾次迴圈,也可透過<vector>[i]取得與該次迴圈對應的元素。#> [1] "1 謝" #> [1] "2 老師" #> [1] "3 好" #> [1] "4 帥"vec <- c("謝", "老師", "好", "帥") for (i in seq_along(vec)) { print(vec[i]) # Print `?` in the last loop if (i == length(vec)) { print('?') } }#> [1] "謝" #> [1] "老師" #> [1] "好" #> [1] "帥" #> [1] "?" -
我們也可以透過
names()在 for loop 裡使用<vector>的 names 屬性:vec <- c(Monday = "rainy", Tuesday = "cloudy", Wednesday = "sunny") for (name in names(vec)) { print(paste0(name, ' was ', vec[name], '.')) }#> [1] "Monday was rainy." #> [1] "Tuesday was cloudy." #> [1] "Wednesday was sunny."
常常我們會需要對 for loop 有「更多的控制」。前面在 for loop 中使用到條件式即是一個例子。但常常條件式本身的功能並不足夠:執行迴圈時,在符合特定條件下,
-
有時候我們會希望能忽略一次迴圈中「所有尚未被執行的程式碼」,這時就會使用到
next:# 使用 next '忽略一次' 迴圈 for (i in 1:10) { if (i == 5) { print("Skipping print(i) if i == 5") next } print(i) }#> [1] 1 #> [1] 2 #> [1] 3 #> [1] 4 #> [1] "Skipping print(i) if i == 5" #> [1] 6 #> [1] 7 #> [1] 8 #> [1] 9 #> [1] 10 -
有時我們需要跳出整個迴圈,亦即不再執行 for loop 裡面的程式碼。這時就會使用到
break:# 使用 break 跳出整個迴圈 for (i in 1:10) { if (i == 5) { print("Breaking out the for loop") break } print(i) }#> [1] 1 #> [1] 2 #> [1] 3 #> [1] 4 #> [1] "Breaking out the for loop"
3.2.2 實際應用:修改檔案名稱
下方的程式碼能將多個檔案 (圖片) 重新命名 (並透過 next 忽略某些檔案)。有興趣者請下載原始碼,裡面有一個資料夾 dice/。執行此程式碼前,需將工作目錄設至 dice/ 資料夾。
for (file in list.files()) {
# 忽略 `00_not_an_img.txt` 這個檔案
if (file == '00_not_an_img.txt') {
next
}
file.rename(from = file, to = paste0('dice-', file))
}3.3 Wrap up:for loop 與 list
-
上週我們使用過 3 個長度為 4 的 vector 來儲存關於 4 個人 (“kai”, “pooh”, “tiger”, “piglet”) 的資料。但使用這種方式儲存資料似乎有些違反直覺,因為它將關於一個人的資訊 (
name與age) 分開來儲存在獨立的 vector。 -
對於這種彼此之間具有關聯的資料,一種更好的方式是將它們儲存在一起,因為這不只幫助我們在「程式上」更容易去操弄這筆資料,更讓我們能以「階層組織」去「想像」我們的資料。這裡我們使用
list去改寫上週的資料:member <- list( list(name = "kai", age = 40), list(name = "pooh", age = 20), list(name = "tiger", age = 18), list(name = "piglet", age = 19) ) member#> [[1]] #> [[1]]$name #> [1] "kai" #> #> [[1]]$age #> [1] 40 #> #> #> [[2]] #> [[2]]$name #> [1] "pooh" #> #> [[2]]$age #> [1] 20 #> #> #> [[3]] #> [[3]]$name #> [1] "tiger" #> #> [[3]]$age #> [1] 18 #> #> #> [[4]] #> [[4]]$name #> [1] "piglet" #> #> [[4]]$age #> [1] 19for (person in member) { name <- person$name age <- person$age # 將組成句子的片語儲存於 char vector `phrases` phrases <- c(name, " is ", age) if (age < 35) { phrases[4] <- ", which is quite young" } # 將各片語連接起來成為一個句子 sentence <- paste0(phrases, collapse = '') print(sentence) }#> [1] "kai is 40" #> [1] "pooh is 20, which is quite young" #> [1] "tiger is 18, which is quite young" #> [1] "piglet is 19, which is quite young"
3.4 data frame
data frame 是 R 語言非常重要的資料結構,它造就了 R 強大的表格式資料處理能力
-
data frame 是一種二維的資料結構。這種資料結構基本上與我們熟悉的 Excel (或 google 試算表) 非常類似:
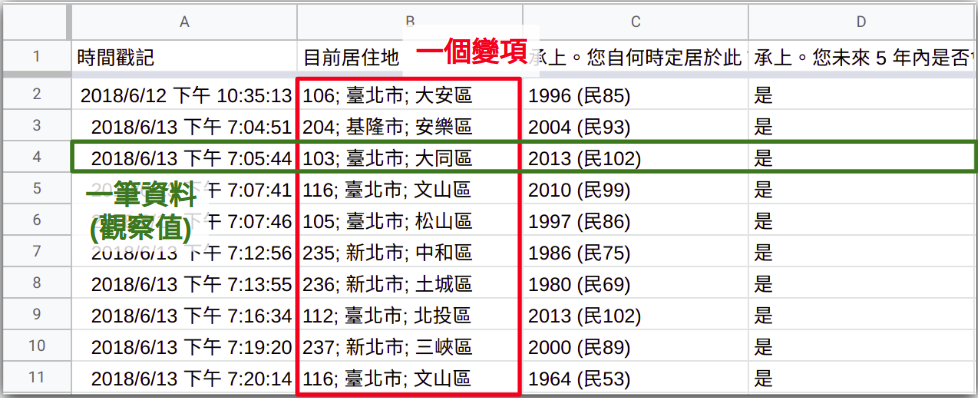
Figure 3.2: A data frame looks like an Excel Spreadsheet
data frame 的每一橫列 (row) 皆是一筆資料 (e.g. 一位受訪者所填的問卷)
data frame 的每一 (直) 欄 (column) 代表一個變項 (e.g. 問卷上的某個題目)
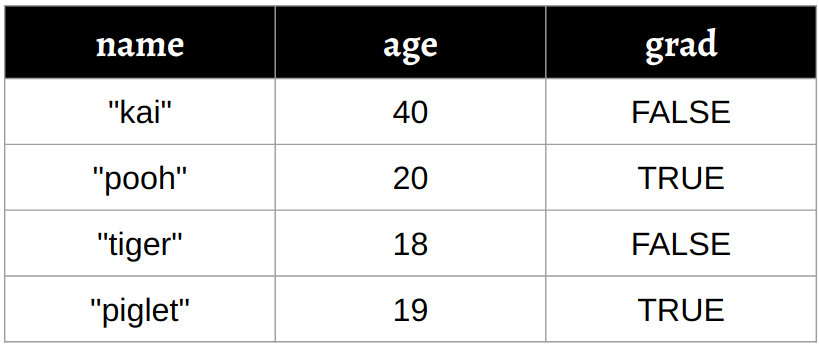
Figure 3.3: A Data Frame
-
我們可以使用
tibble套件的tibble()11 建立 data frame。上圖中的 data frame 例子即可由下方的程式碼所建立:library(tibble) df <- tibble(name = c("kai", "pooh", "tiger", "piglet"), age = c(40, 20, 18, 19), grad = c(FALSE, TRUE, FALSE, TRUE)) df#> # A tibble: 4 x 3 #> name age grad #> <chr> <dbl> <lgl> #> 1 kai 40 FALSE #> 2 pooh 20 TRUE #> 3 tiger 18 FALSE #> 4 piglet 19 TRUE-
tibble()裡的每個 vector 對映到 data frame 中的一欄 (column)。因此 data frame 中不同欄的資料類型可能不同,但每一欄 (變項) 內的資料類型必須相同 (因為 vector 只能儲存相同的資料類型)。
-
-
下方的指令可用於檢視 data frame 的資訊
nrow(df) # number of rows ncol(df) # number of columns dim(df) # 形狀 (num of rows, num of columns) names(df) # name of each column#> [1] 4 #> [1] 3 #> [1] 4 3 #> [1] "name" "age" "grad"tibble::glimpse(df) # 關於 df 的各種資訊#> Rows: 4 #> Columns: 3 #> $ name <chr> "kai", "pooh", "tiger", "piglet" #> $ age <dbl> 40, 20, 18, 19 #> $ grad <lgl> FALSE, TRUE, FALSE, TRUEstr(df) # 也可用 Base R 內建函數: str()#> tibble [4 × 3] (S3: tbl_df/tbl/data.frame) #> $ name: chr [1:4] "kai" "pooh" "tiger" "piglet" #> $ age : num [1:4] 40 20 18 19 #> $ grad: logi [1:4] FALSE TRUE FALSE TRUEView(df) # View data frame in RStudio source pane
3.4.1 Subsetting: returning a data frame
-
data frame 的篩選 (subsetting) 與 vector 和 list 類似,差別只在於 data frame 屬於二維的資料結構,因此需要提供 2 個 vector 進行資料的篩選:
df[<vector 1>, <vector 2>]在這裡,
<vector 1>篩選的是「列 (row)」,亦即,<vector 1>決定要篩選出哪幾個觀察值 (observations)。<vector 2>篩選的則是「欄 (column)」,亦即,<vector 2>決定要篩選出哪些變項 (variables)。以這種語法進行篩選,回傳的一定是 data frame12,即使只有篩選出一個值 (e.g. df[1, 1])
df[2, 1]#> # A tibble: 1 x 1
#> name
#> <chr>
#> 1 pooh
df[2, 1:2] # df[2, c("name", "age")]#> # A tibble: 1 x 2
#> name age
#> <chr> <dbl>
#> 1 pooh 20
df[2, ]#> # A tibble: 1 x 3
#> name age grad
#> <chr> <dbl> <lgl>
#> 1 pooh 20 TRUE3.4.2 Subsetting: returning a vector
-
若想要從 data frame 裡面篩選出 vector (取得「火車車廂」內的值),則要使用之前提過的
$或[[]]:df[[2]] # df[[<column_index>]] df[["age"]] # df[["<column_name>"]] df$age # df$<column_name>, 最常見#> [1] 40 20 18 19 #> [1] 40 20 18 19 #> [1] 40 20 18 19 -
篩選 data frame 而回傳 vector 是個很實用的技巧,因為我們可以使用這個回傳的 vector 當作我們進一步篩選 data frame 的依據,例如:
over19 <- df$age > 19 over19#> [1] TRUE TRUE FALSE FALSE# subset df with obs. over 19 df[over19, ]#> # A tibble: 2 x 3 #> name age grad #> <chr> <dbl> <lgl> #> 1 kai 40 FALSE #> 2 pooh 20 TRUE# subset df with obs. below or equal 19 df[!over19, ]#> # A tibble: 2 x 3 #> name age grad #> <chr> <dbl> <lgl> #> 1 tiger 18 FALSE #> 2 piglet 19 TRUE# 合併起來寫 (最常見的寫法,但比較難讀懂) df[df$age > 19, ]#> # A tibble: 2 x 3 #> name age grad #> <chr> <dbl> <lgl> #> 1 kai 40 FALSE #> 2 pooh 20 TRUE -
透過這個技巧,R 能幫助我們快速篩選出需要的資料,例如,我們可以結合
age與grad兩個變項,篩選出「小於 20 歲且為研究所學生」的 data frame:df[(df$age < 20) & (df$grad), ]#> # A tibble: 1 x 3 #> name age grad #> <chr> <dbl> <lgl> #> 1 piglet 19 TRUE