8 中文文本資料處理
8.1 斷詞
jieba 是一個用於中文斷詞的 (Python) 套件。jiebaR 則是 jieba 的 R 版本。
使用 jiebaR 進行斷詞只須兩個步驟:
-
jiebaR::segment()回傳一個 character vector,vector 內的每個元素都是一個被斷出來的詞:#> [1] "失業" "的熊" "讚" "陪" "柯文" "哲看" "銀翼" "殺手" -
jiebaR的斷詞有時會不太精準,尤其是遇到專有名詞或是特殊詞彙時,這些詞彙時常會被斷開。若想避免這種情況,可以新增一份自訂辭典 (儲存在一份純文字檔,每個詞佔一行),例如user_dict.txt的內容如下:熊讚 柯文哲 銀翼殺手如此在
worker()中設定自訂辭典,jiebaR就不會將這些詞彙斷開:#> [1] "失業" "的" "熊讚" "陪" "柯文哲" "看" "銀翼殺手"
8.2 使用 data frame 建立語料庫
我們的目標是建立一個 data frame 儲存文本資料。在這個 data frame 中,每一個 row 代表一篇文章,每個變項 (column) 記錄著該篇文章的某個資訊。根據文本資料的來源,該 data frame 可能會有不同數量的變項,例如,「文章發表日期」、「作者」、「標題」、「主題」等。但最重要的是,此 data frame 至少需具備兩個變項 — 「文章 id」與「(斷完詞的) 文章內文」。下方使用一個簡單的例子 (3 篇文章) 說明如何建立這種 data frame。
-
第一步是將
docs內的各篇文章 (character vector) 進行斷詞,並在斷完詞後,將文章的內容存入另一個等長的 character vector 中。同篇文章中,被斷開的詞之間以一個全形空白字元分隔:library(jiebaR) # Data: 3 篇文章 docs <- c( "蝴蝶和蜜蜂們帶著花朵的蜜糖回來了,羊隊和牛群告別了田野回家了,火紅的太陽也滾著火輪子回家了,當街燈亮起來向村莊道過晚安,夏天的夜就輕輕地來了。", "朋友買了一件衣料,綠色的底子帶白色方格,當她拿給我們看時,一位對圍棋十分感與趣的同學說:「啊,好像棋盤似的。」「我看倒有點像稿紙。」我說。「真像一塊塊綠豆糕。」一位外號叫「大食客」的同學緊接著說。", "每天,天剛亮時,我母親便把我喊醒,叫我披衣坐起。我從不知道她醒來坐了多久了。她看我清醒了,便對我說昨天我做錯了什麼事,說錯了什麼話,要我認錯,要我用功讀書。" ) # Initialize jiebaR seg <- worker() docs_segged <- vector("character", length = length(docs)) for (i in seq_along(docs)) { # Segment each element in docs segged <- segment(docs[i], seg) # Collapse the character vector into a string, separated by space docs_segged[i] <- paste0(segged, collapse = "\u3000") } docs_segged#> [1] "蝴蝶 和 蜜蜂 們 帶 著 花朵 的 蜜糖 回來 了 羊隊 和 牛群 告別 了 田野 回家 了 火紅 的 太陽 也 滾 著火 輪子 回家 了 當 街燈 亮 起來 向 村莊 道過 晚安 夏天 的 夜 就 輕輕地 來 了" #> [2] "朋友 買 了 一件 衣料 綠色 的 底子 帶 白色 方格 當 她 拿給 我們 看時 一位 對 圍棋 十分 感與趣 的 同 學說 啊 好像 棋盤 似的 我 看 倒 有點像 稿紙 我 說 真 像 一塊塊 綠豆糕 一位 外號 叫 大 食客 的 同學 緊接著 說" #> [3] "每天 天剛亮 時 我 母親 便 把 我 喊醒 叫 我 披衣 坐起 我 從不 知道 她 醒來 坐 了 多久 了 她 看 我 清醒 了 便 對 我 說 昨天 我 做 錯 了 什麼 事 說錯 了 什麼 話 要 我 認錯 要 我 用功讀書" -
如此,我們就能使用這個斷完詞的
docs_segged製作 data frame:docs_df <- tibble::tibble( doc_id = seq_along(docs_segged), content = docs_segged ) knitr::kable(docs_df, align = "c")doc_id content 1 蝴蝶 和 蜜蜂 們 帶 著 花朵 的 蜜糖 回來 了 羊隊 和 牛群 告別 了 田野 回家 了 火紅 的 太陽 也 滾 著火 輪子 回家 了 當 街燈 亮 起來 向 村莊 道過 晚安 夏天 的 夜 就 輕輕地 來 了 2 朋友 買 了 一件 衣料 綠色 的 底子 帶 白色 方格 當 她 拿給 我們 看時 一位 對 圍棋 十分 感與趣 的 同 學說 啊 好像 棋盤 似的 我 看 倒 有點像 稿紙 我 說 真 像 一塊塊 綠豆糕 一位 外號 叫 大 食客 的 同學 緊接著 說 3 每天 天剛亮 時 我 母親 便 把 我 喊醒 叫 我 披衣 坐起 我 從不 知道 她 醒來 坐 了 多久 了 她 看 我 清醒 了 便 對 我 說 昨天 我 做 錯 了 什麼 事 說錯 了 什麼 話 要 我 認錯 要 我 用功讀書
8.3 tidytext framework
tidytext套件是 R 生態圈中比較近期的 text mining 套件,它將 tidyverse 的想法運用到文本資料處理上,換言之,就是使用 data frame 的資料結構去表徵和處理文本資料。-
使用
tidytext的方法處理文本資料有好有壞。好處是使用者能輕易地結合
dplyr與ggplot2於文本分析中,因而能快速地視覺化文本資料。-
壞處是,在
tidytextframework 之下,文章的內部 (i.e. 詞彙與詞彙之間的) 結構會消失,因為它對於文本的想法是 bag-of-words。tidytext所倡導的儲存文本資料的格式是 one-token-per-document-per-row,亦即,在一個 data frame 中,每一橫列 (row) 是一篇文章中的一個 token。因此,若有兩篇文章,第一篇被斷成 38 個詞彙,第二篇被斷成 20 個詞彙,則共需要一個 58 列 (row) 的 data frame 來儲存這兩篇文章。
一般而言,tidytext 的架構適合用於與詞頻有關的分析,例如,計算文章的 lexical diversity 或是透過情緒詞的詞頻進行情緒分析。
-
透過
tidytext::unnest_tokens(),可以將docs_df中儲存之 (已斷詞) 文本資料,變成 tidytext format,i.e.,one-token-per-document-per-row 的 data frame:library(tidytext) library(dplyr) tidy_text_format <- docs_df %>% unnest_tokens(output = "word", input = "content", token = "regex", pattern = "\u3000") # 以空白字元作為 token 分隔依據 tidy_text_format#> # A tibble: 139 x 2 #> doc_id word #> <int> <chr> #> 1 1 蝴蝶 #> 2 1 和 #> 3 1 蜜蜂 #> 4 1 們 #> 5 1 帶 #> 6 1 著 #> 7 1 花朵 #> 8 1 的 #> 9 1 蜜糖 #> 10 1 回來 #> # … with 129 more rows
8.3.1 詞頻表
-
可以使用
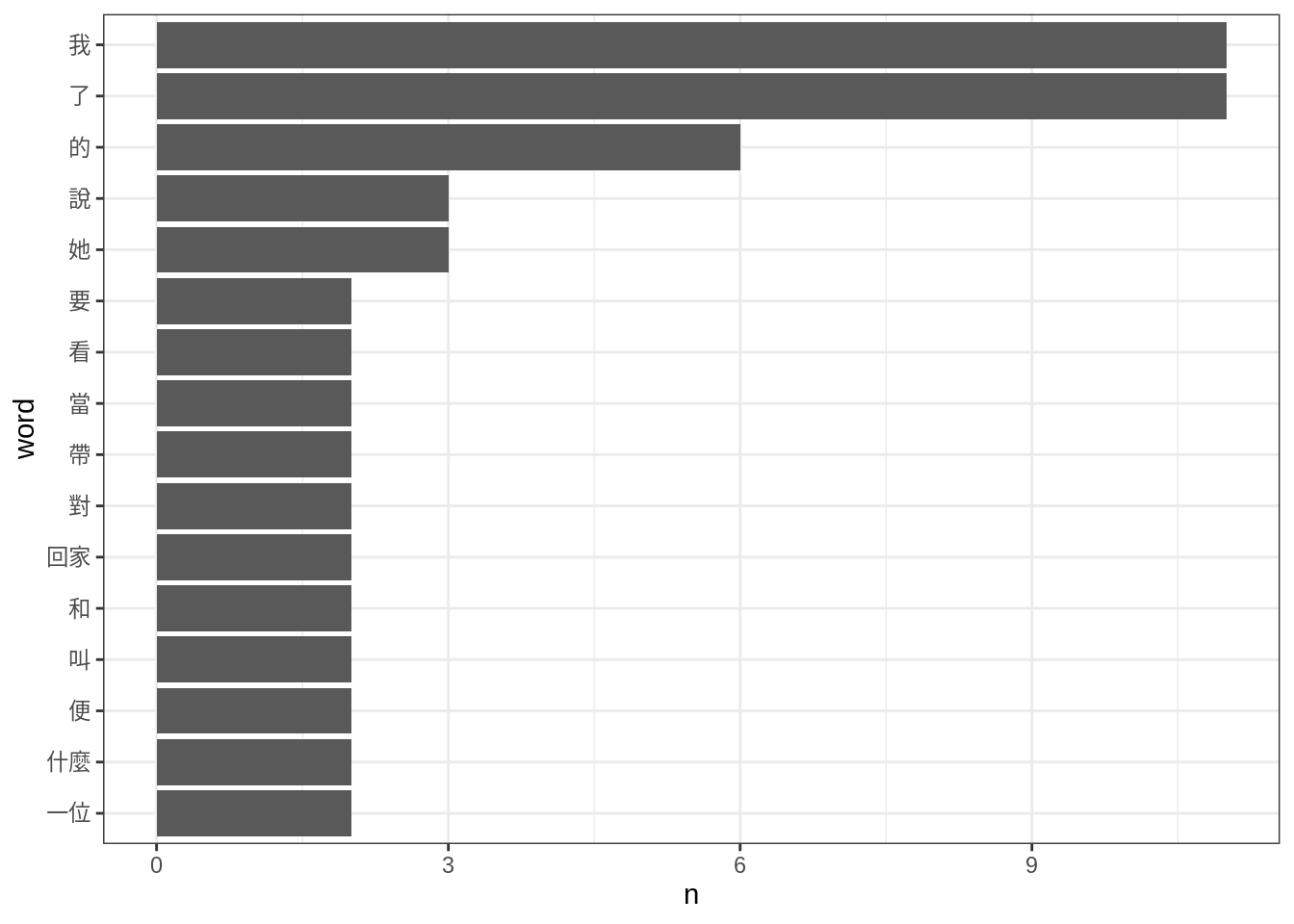
dplyr的group_by()與summarise()計算詞頻表:#> # A tibble: 99 x 2 #> word n #> <chr> <int> #> 1 了 11 #> 2 我 11 #> 3 的 6 #> 4 她 3 #> 5 說 3 #> 6 一位 2 #> 7 什麼 2 #> 8 便 2 #> 9 叫 2 #> 10 和 2 #> # … with 89 more rows#> # A tibble: 99 x 2 #> word n #> <chr> <int> #> 1 了 11 #> 2 我 11 #> 3 的 6 #> 4 她 3 #> 5 說 3 #> 6 一位 2 #> 7 什麼 2 #> 8 便 2 #> 9 叫 2 #> 10 和 2 #> # … with 89 more rows
8.4 quanteda framework
傳統 R 的 text mining 生態圈中,使用的是另一種 (高階) 資料結構儲存文本資料 — 語料庫 (corpus)。不同的套件有自己定義 corpus 的方式,且各自進行文本分析的流程與想法差異頗大。目前最流行、支援最多的兩個套件是 quanteda 與 tm。其中,quanteda 在中文支援以及說明與教學文件的完整度較高。
下方為 quanteda 套件的一些使用範例。欲比較完整地了解 quanteda,請閱讀 quanteda tutorials。
- 使用
quanteda的好處在於它保留了文章的內部結構,例如,可以透過quanteda::kwic()去檢視特定詞彙或是片語出現的語境。與此同時,quanteda也提供許多 bag-of-words 想法之下的函數。 - 但
quanteda的缺點在於其內容龐雜,需要一些語料庫語言學的背景知識以及相當的時間摸索才能掌握。
library(quanteda)
# 將 data frame 轉換成 Corpus object
quanteda_corpus <- corpus(docs_df,
docid_field = "doc_id",
text_field = "content")-
# tokenize the corpus q_tokens <- tokenizers::tokenize_regex(quanteda_corpus, "\u3000") %>% tokens() kwic(q_tokens, "我", window = 5, valuetype = "regex") %>% knitr::kable(align = "c")docname from to pre keyword post pattern 2 15 15 白色 方格 當 她 拿給 我們 看時 一位 對 圍棋 十分 我 2 29 29 學說 啊 好像 棋盤 似的 我 看 倒 有點像 稿紙 我 我 2 34 34 我 看 倒 有點像 稿紙 我 說 真 像 一塊塊 綠豆糕 我 3 4 4 每天 天剛亮 時 我 母親 便 把 我 喊醒 我 3 8 8 時 我 母親 便 把 我 喊醒 叫 我 披衣 坐起 我 3 11 11 便 把 我 喊醒 叫 我 披衣 坐起 我 從不 知道 我 3 14 14 喊醒 叫 我 披衣 坐起 我 從不 知道 她 醒來 坐 我 3 25 25 了 多久 了 她 看 我 清醒 了 便 對 我 我 3 30 30 我 清醒 了 便 對 我 說 昨天 我 做 錯 我 3 33 33 便 對 我 說 昨天 我 做 錯 了 什麼 事 我 3 44 44 說錯 了 什麼 話 要 我 認錯 要 我 用功讀書 我 3 47 47 話 要 我 認錯 要 我 用功讀書 我